Sensitive information includes PII such as names, addresses, government issued identity cards, medical and financial information, any data that could be used to identify an individual or any business critical data.
SITs in Microsoft 365 are called pattern-based classifiers, this means SITs are used to identify data within the information, example credit card numbers within email body.
Sensitive information types looks for patterns and validate data by looking at the relevant keywords, the format of the data, and its checksum.
These SITs can then be used in various Microsoft Purview solutions like DLP policies, Content Explorer, Communication Compliance, Auto-Labelling policies and other services in Microsoft 365 to detect and classify sensitive items in emails and files.
Table of contents
Types of Sensitive Information Types.
Below are the different types of SITs in Microsoft 365.
Built-in SIT.
Microsoft 365 has more than 100 pre defined SITs available in Microsoft Purview portal, It cannot be edited but can be copied to create a new SIT. The built in SIT includes commonly used sensitive data like employee ID, physical address, full names.
check the article Sensitive information type entity definitions to get the list of the pre defined Sensitive Information Types in Microsoft 365.
Custom SIT.
An organization can create a new custom SIT or copy a built in SIT and modify it, if the organizations compliance requirements cannot be fulfilled with the built in SIT. Lets say the organization wants to block the Indian phone number, they can create the custom SIT using Regex that will capture the Indian phone number in the data and use the custom SIT in DLP policy. Another example of custom SIT is when the organization wants to block urls or websites in the data.
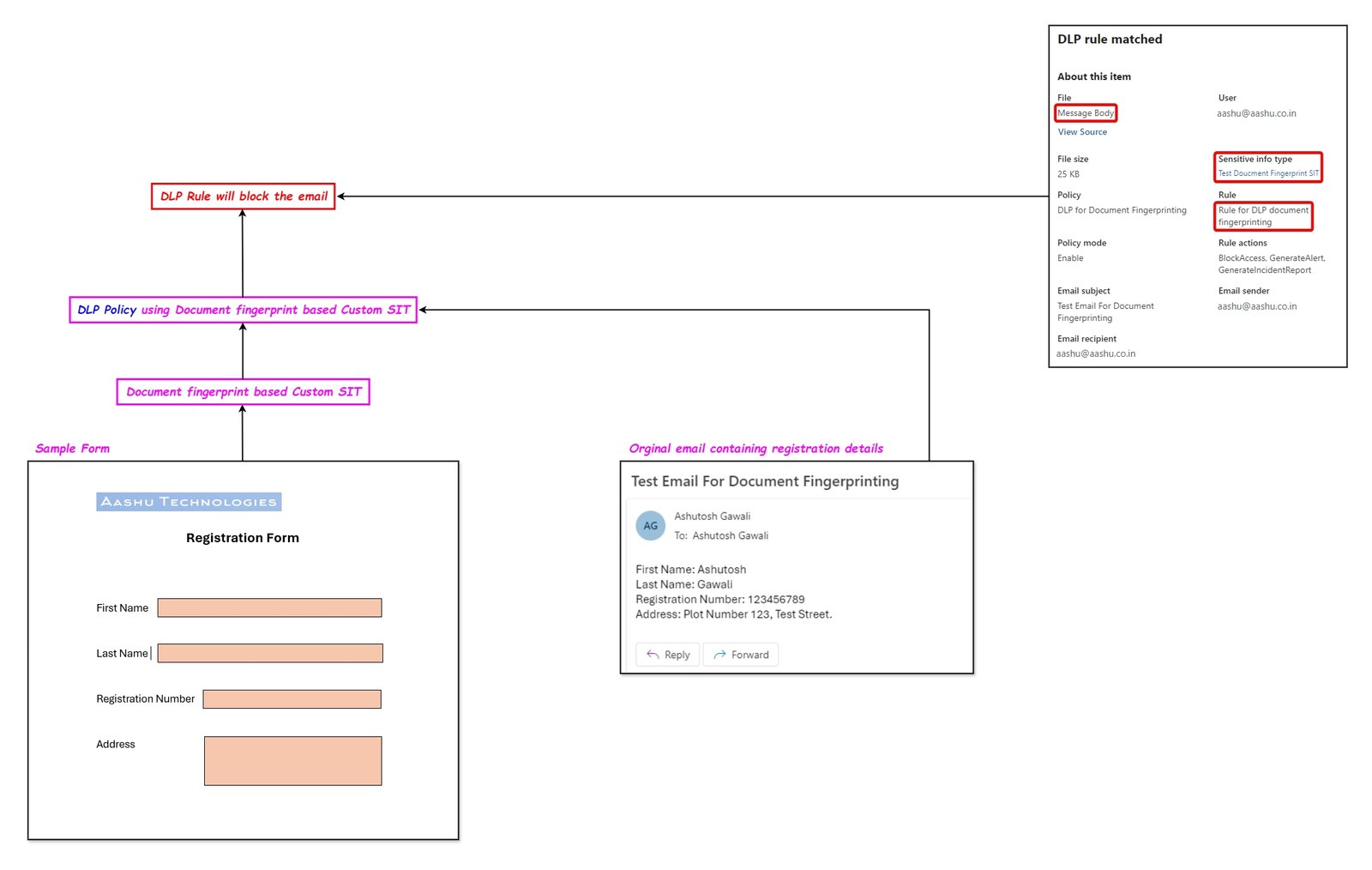
Document fingerprint based SIT.
Using document fingerprinting process, an organization converts an internal form (which is used to save the sensitive information) into a sensitive information type. Example: lets say the organization has the below format to save the customers information internally, the organization creates a SIT using document fingerprinting. DLP policy is created to match the custom document fingerprinting based SIT and block the emails containing the data with the internal format.
Exact Data Match (EDM) based SIT.
EDM based SIT will block the exact sensitive data instead of the generic pattern (like in built in and custom SIT). The organization will create an EDM based SIT by uploading a database of sensitive information which the organization wants to block. Note that the actual data is not uploaded to the Microsoft 365 SIT database, a hash of the original sensitive data will be uploaded and then the hash value is checked against the potential sensitive data.
Learn about exact data match based sensitive information types
Sensitive information type components.
When you create a new SIT, you will be asked to create at least 1 pattern. Pattern defines what a SIT will detect. Below are the components which creates a pattern in SIT.
Primary Element.
This is the main info an organization wants to detect in content. In a primary element, you can define the below.
- Regular Expressions (regex): A pattern of numbers, characters and special characters that the Microsoft’s regular expression engine attempts to match (detect) in the content. You can use websites like Regex101 or RegExr to test the regular expression you create against dummy data.
- Validators (Optional): Validators are the functions used to perform additional validations on the regular expression pattern. It helps to ensure that the detected data is not just similar to sensitive information but is a valid match. Examples are Checksum validator, Luhn check validator, and Functional processors validator.
- Keyword Lists: The specific words and phrases you want this SIT to detect.
- Keyword Dictionary: Multiple keywords are grouped into a file.
- Functions: Pre built operations that are used to recognize and validate patterns of sensitive data. Example the pre built function named Func_credit_card detects the credit card number.
Supporting Elements.
Adding the supporting elements increases the possibility that the detected info is a match for SIT. Example, lets say, the organization wants to block credit card in the email and they are using Credit Card SIT. If the email contains any 16 digits random number, it does not mean the 16 digit number is credit card, so you can add the supporting element (words) like card identification number or transaction number near the 16 digits random number so that the possibility of the random number be considered as credit card will increase.
When the primary element is matched, any supporting elements will match only when found within the character proximity to the primary element.
Character Proximity.
It shows how closer the supporting element should be to the primary element, The closer the primary and supporting elements are to each other, the more likely the detected content is going to be what you’re looking for.
If you select 300 characters, then if supporting element should be withing 300 characters from the primary element, only then the detected content will be considered as a match.
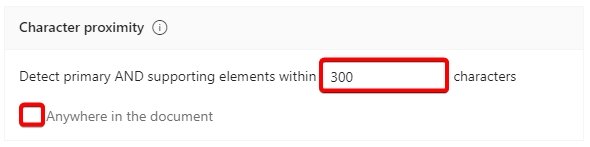
If you select anywhere in the document, and if the data is specified anywhere in the document, then it will be considered as match.
Additional Checks.
In this option, you can add specific exclusion or include specific text / patterns to fine tune the detection of the primary element.
Below are the options we get when selecting additional checks.
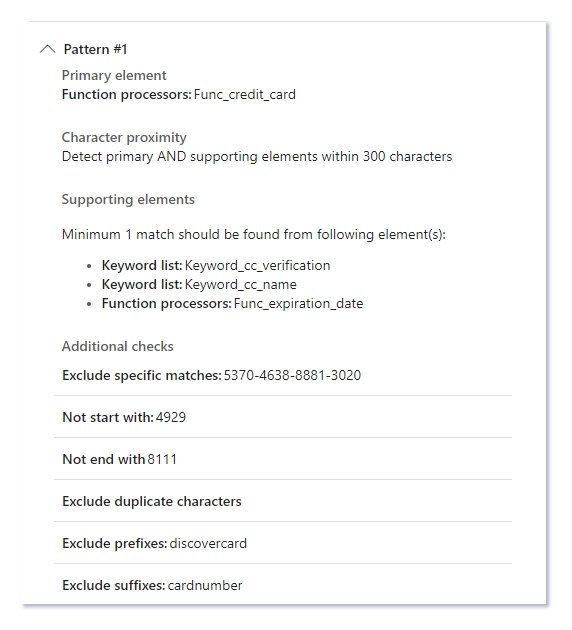
- Exclude specific matches: you can exclude the specific dummy credit card number like ‘5370-4638-8881-3020’ so they are not matched as a valid credit card number.
- Starts or doesn’t start with characters: If the organization wants to only detect the credit cards starting with digits 4929 then select the option starts with character. If the organization does not want the credit card starting with the digit 4929 to be detected in the document then select doesn’t start with characters.
- Ends or doesn’t end with characters: If the organization wants only to detect the credit cards the ends with digit 8111, then select the option ends with characters. If the organization does not want the credit card that ends with digit 8111 to be matched then select the option doesn’t ends with characters.
- Exclude duplicate characters: Selecting this option will exclude any number that has duplicates. Example the dummy credit card number 4916-4444-9269-8783 has the duplicate 4444. The dummy credit card number will not be a match, while on the other hand the dummy credit card number 4532-1753-6071-1112 also contains duplicate 111, but it will be considered as match.
- Include or exclude prefixes: If the organization wants only the credit card numbers written after the a specific keyword (example: master card) to be considered as a match then use the option Include prefixes. example: the dummy credit card data (master card 5299-1561-5689-1938) will not be considered as a match. If the organization does not wants the credit card numbers written after the a specific keyword (example: discovercard) to be considered as a match, then use the option exclude prefixes. example: the dummy credit card data (discovercard 5299-1561-5689-1938) will not be considered as a match.
- Include or exclude suffixes: If the organization only wants the credit card numbers written before a specific keyword (example: BrandSmart) to be considered as a match then use the option Include suffixes. example: the dummy credit card data (5293-8502-0071-3058 BrandSmart) will be considered as a match. If the organization does not want wants the credit card numbers written before a specific keyword (example: cardnumber) to be considered as a match, then use the option exclude suffixes. example: the dummy credit card data (5293-8502-0071-3058 cardnumber) will not be considered as a match.
Confidence Level.
Confidence levels (low, medium, high) indicate the amount of supporting elements found with the combination of sensitive data. The confidence increases when supporting elements are detected along with the primary element.
low confidence triggers for an unformatted number. example any 16 digit number may be considered as a valid credit card number.
medium confidence needs the digits separated by dashes. example the dummy credit card number 4916-4444-9269-8783 can be considered as a valid credit card number.
high confidence only triggers if there are additional keywords present in the content. example the keyword credit card number 4916-4444-9269-8783.
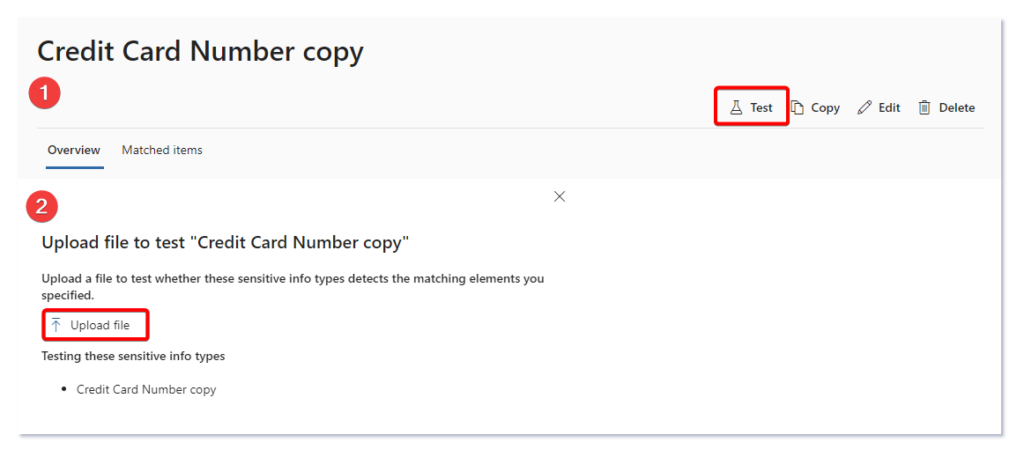
Test the Custom SIT.
After creating a custom SIT or editing the copied built in SIT, you will get the option to Test the SIT, create a sample txt file with dummy sensitive data, upload the file to confirm if the newly created custom SIT matches the test data in the txt file.
I have copied the credit card SIT and I am using the website https://dlptest.com/sample-data/ to get the dummy sensitive data for testing.
Below are the settings of the custom test credit card SIT.
Below is the test data I am using to test the custom SIT.
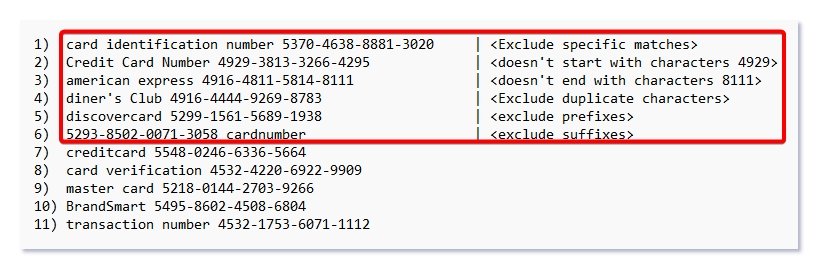
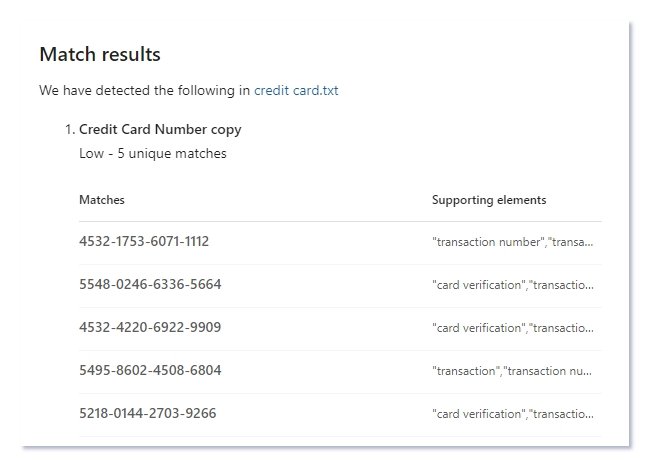
After uploading the txt file with the above dummy content for testing the custom SIT, you will on get the matches for the credit card from the line number 7 to line number 11, as the data in the line 1 to 6 is already excluded in the additional checks for the custom SIT.
Thank you